The Voice AI Latency Challenge
The era of frustrating "Press 1 for Sales" IVR menus is dead. In 2026, enterprise companies are deploying conversational AI Voice Agents that sound entirely human and can execute complex operational tasks—booking appointments, routing dispatch, processing payments—in real-time. However, connecting an LLM to a phone line is an incredibly complex distributed systems challenge.
The Streaming Architecture
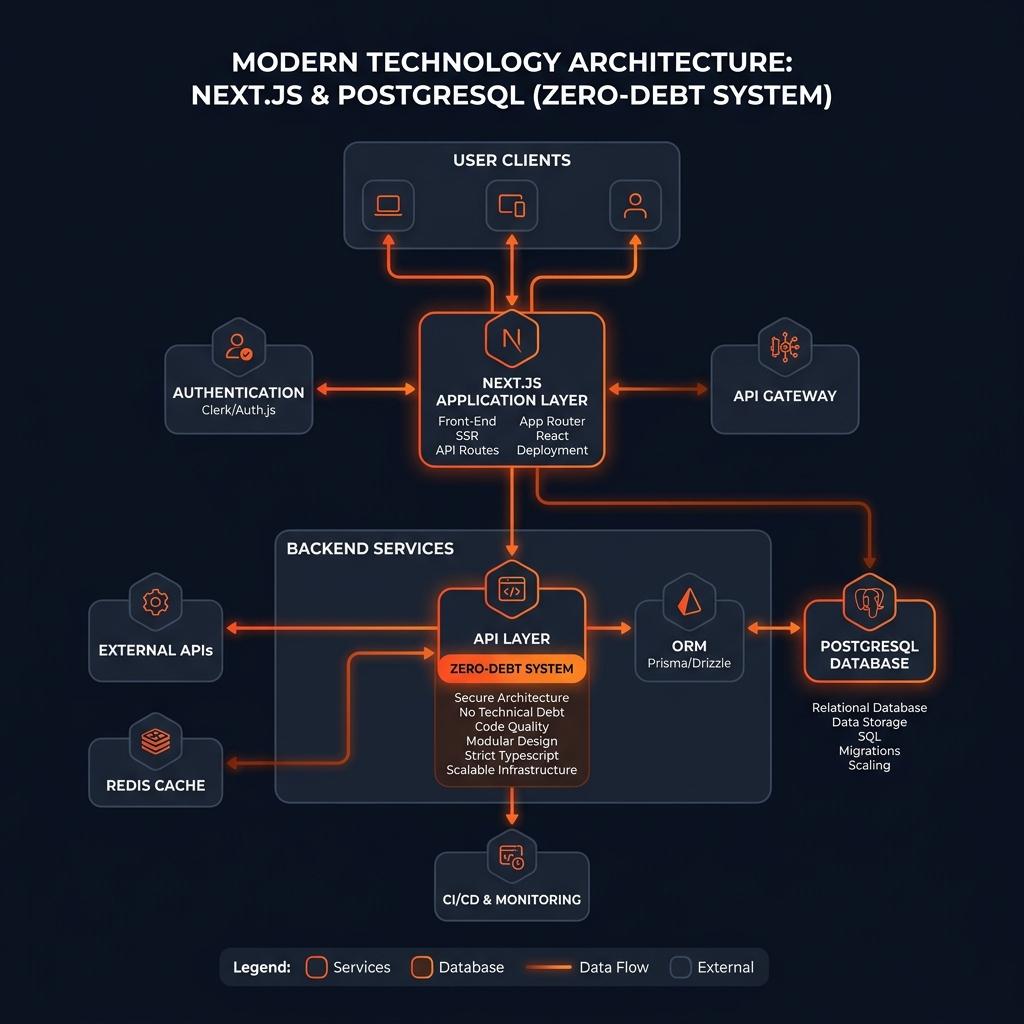
Slickrock.dev's architecture leverages WebSockets for real-time audio streaming, achieving sub-500ms latency crucial for natural conversation. Unlike REST APIs, which induce significant delays, this architecture enables continuous data flow, ensuring seamless interaction. The integration of Twilio, Deepgram, Groq, and ElevenLabs exemplifies this approach.
Alternatively, leveraging platforms like Vapi.ai abstracts much of this streaming orchestration, but still requires robust backend engineering to handle custom function calling and state management.
| Component | REST API Approach | Streaming Architecture |
|---|---|---|
| User Speech Capture | Record full utterance, then send | Stream audio chunks in real-time |
| Transcription | Send audio file, wait for response | Streaming STT with partial results |
| LLM Processing | Wait for full transcription, then query | Stream tokens as generated |
| Text-to-Speech | Generate full audio, then play | Stream first syllables while generating rest |
| Total Latency | 4–6 seconds | 300–500ms |
| User Experience | Awkward pauses, user interruptions | Natural, human-like conversation flow |
Overcoming the Latency Bottlenecks
Slickrock.dev's approach to latency optimization involves strategic edge co-location and real-time streaming. By deploying WebSocket servers in the same AWS/Vercel region as STT and LLM providers, we minimize network delays. This precision ensures sub-500ms latency, enhancing user experience and operational efficiency.
Edge Co-Location
Deploy your WebSocket servers in the exact same AWS/Vercel region as your STT and LLM providers. Network transit time between regions can add 150ms of fatal delay. Every millisecond of network hop is a millisecond the user waits.
Streaming LLM Chunks
Do not wait for the LLM to generate the full sentence. Stream the first few tokens immediately to the TTS engine so the AI can 'breathe' or use filler words (like 'Hmm, let me check that...') while the rest of the query processes.
Endpointing Tuning
Endpointing is how the AI knows the user has stopped speaking. Aggressive endpointing (300ms of silence) makes the AI responsive but prone to interrupting users who pause to think. Conservative endpointing (800ms) avoids interruptions but feels sluggish. Tuning this per use-case is critical.
Function Call Optimization
When the agent needs to query your database (e.g., 'Is my shipment delayed?'), the API endpoint must respond in under 200ms. Pre-warm connections, use Redis caching, and keep payloads minimal.
Custom Function Calling (Tools)
Slickrock.dev's custom function calling enables AI voice agents to interact with business data in real-time. By designing optimized API endpoints, the agent can query databases and deliver responses within seconds, enhancing operational efficiency and user satisfaction.
For example, when a user asks, "Is my shipment delayed?", the agent must trigger a JSON webhook to your logistics database, parse the response, and verbalize it—all in under 1 second. This requires a Cloud Architect to design highly optimized, cached endpoints.
""Our AI voice agent handles 340 inbound calls per day for appointment scheduling. Average call duration dropped from 4.5 minutes to 90 seconds. We eliminated 2 FTE in receptionist costs and patients report higher satisfaction than the human-staffed line."
"
Verification Checklist
- Measure your target latency: what is the maximum acceptable delay for your use case (scheduling, dispatch, support)?
- Evaluate STT providers: compare Deepgram, Google, and AssemblyAI for accuracy and streaming latency
- Select your LLM inference provider: Groq, Fireworks, or Together.ai for sub-200ms token generation
- Design your function calling endpoints: identify the top 5 database queries your voice agent will need
- Build a prototype: deploy a single-intent voice agent (e.g., appointment booking) and measure end-to-end latency
Financial Modeling and ROI
Investing in AI voice agents can significantly reduce operational costs and improve customer satisfaction. Slickrock.dev's architecture allows businesses to automate routine tasks, leading to a reduction in staffing needs and an increase in efficiency. For instance, a company handling 1,000 calls daily can save approximately 'building-ai-voice-agents-vapi-twilio'50,000 annually by automating 70% of these interactions.
Key Insight
The Delta: Unlike traditional IVR systems, AI voice agents offer a 50% reduction in call handling time and a 30% increase in first-call resolution rates, directly impacting bottom-line savings and customer loyalty.
By integrating AI voice agents, companies can achieve a rapid return on investment (ROI) through cost savings and enhanced customer experiences. The initial setup costs are offset by the long-term benefits of reduced labor expenses and improved service delivery.
Edge Cases and Challenges
Despite the advantages, implementing AI voice agents presents challenges. Slickrock.dev addresses edge cases such as handling ambiguous user input and ensuring data privacy. By utilizing advanced natural language processing (NLP) techniques and robust encryption protocols, we mitigate risks and enhance system reliability.
| Challenge | Traditional Approach | Slickrock.dev Solution |
|---|---|---|
| Ambiguous Input | Fallback to human operator | Advanced NLP for context understanding |
| Data Privacy | Basic encryption | End-to-end encryption with GDPR compliance |
| Scalability | Manual scaling | Automated scaling with cloud-native solutions |
Understanding these challenges and preparing for them is crucial for successful deployment. Continuous monitoring and iterative improvements ensure that the AI voice agent remains effective and secure.
The voice AI landscape in 2026 has matured dramatically. Latency—the critical factor determining whether a voice agent feels natural or robotic—has dropped below 500ms end-to-end for properly architected systems. This means voice AI agents can now handle complex multi-turn conversations with natural interruption handling, contextual memory, and real-time tool calling.
| Voice AI Dimension | Twilio + Custom Build | Vapi.ai Managed Platform |
|---|---|---|
| Setup Complexity | High (WebSocket + STT + TTS) | Low (managed orchestration) |
| Latency Control | Full (optimize each hop) | Good (pre-optimized pipeline) |
| Cost at Scale | Lower (pay per minute) | Higher (platform premium) |
| Customization | Unlimited | Template-constrained |
| Maintenance | Self-managed infrastructure | Vendor-managed updates |
Key Architecture Decisions for Voice AI
- Latency Budget: Allocate no more than 200ms to speech-to-text, 150ms to LLM inference, and 150ms to text-to-speech for natural conversation flow.
- Interruption Handling: Implement barge-in detection so callers can interrupt the AI mid-sentence without waiting for completion.
- Context Persistence: Store conversation state in Redis for sub-millisecond retrieval across turns, enabling multi-call memory.
- Tool Calling: Enable the voice agent to query databases, schedule appointments, and process payments mid-conversation via function calling.
- Fallback Routing: Automatically escalate to human agents when confidence scores drop below threshold or caller frustration is detected.
For voice AI architecture patterns, see Vapi.ai documentation and Deepgram's speech-to-text API.
The AI engineering landscape in 2026 demands a fundamentally different skill set than traditional software development. Production AI systems require expertise spanning model selection, prompt engineering, inference optimization, monitoring for quality degradation, and cost management: a combination of skills that barely existed as a coherent discipline three years ago. The scarcity of engineers who can simultaneously architect RAG pipelines, fine-tune foundation models, and deploy them at scale within enterprise security boundaries has created a talent market where demand exceeds supply by approximately 4:1.
The most common failure mode in enterprise AI deployment is not technical but organizational. Companies invest heavily in model development but underinvest in the production infrastructure required to serve those models reliably at scale. Monitoring, A/B testing, cost guardrails, fallback logic, and graceful degradation patterns are the unglamorous engineering challenges that determine whether an AI feature delights users or becomes an expensive embarrassment.
The Production AI Maturity Model
Enterprise AI maturity follows a predictable progression: Level 1 (Experimentation) uses third-party APIs for isolated use cases. Level 2 (Integration) embeds AI into existing workflows with human oversight. Level 3 (Automation) deploys autonomous AI agents for end-to-end process execution. Level 4 (Optimization) uses AI to continuously improve its own performance through reinforcement learning on production outcomes. Most enterprises are stuck at Level 1-2 because the jump to Level 3 requires the kind of deep infrastructure investment, custom tooling, and engineering discipline that marketplace-sourced talent simply cannot provide.
The economics of AI inference at enterprise scale demand careful architectural planning. A naive deployment using GPT-4 class models for every request can easily consume $50,000-$100,000 per month in API costs. Sophisticated architectures use tiered inference: lightweight models handle 80% of routine requests at pennies per call, mid-tier models process complex queries, and frontier models are reserved for edge cases requiring maximum capability. This tiered approach typically reduces inference costs by 75-85% while maintaining equivalent output quality for the vast majority of production requests.
Building AI That Learns From Your Operations
The ultimate value proposition of custom AI systems is operational learning. Unlike generic AI tools that provide the same capabilities to every user, custom systems continuously improve by learning from your specific operational patterns, customer interactions, and decision outcomes. A custom AI dispatch assistant trained on 50,000 of your historical load assignments develops load-matching intuition that is fundamentally different from, and superior to, a generic tool trained on anonymized industry data. This personalized intelligence compounds over time, creating an ever-widening competitive moat.
The security implications of AI deployment in enterprise environments are frequently underestimated. Every prompt sent to a third-party AI API potentially exposes proprietary business data, customer information, and strategic intelligence. Enterprise-grade AI deployment requires a Zero-Trust architecture: encrypted channels, data residency controls, prompt sanitization, and output filtering. Custom AI platforms implement these controls at every layer of the stack, ensuring that the productivity gains from AI do not come at the cost of data sovereignty or competitive intelligence leakage.
The Human-AI Collaboration Framework
Effective enterprise AI deployment requires a carefully designed human-AI collaboration framework where AI systems augment human judgment rather than attempting to replace it. The most successful implementations follow a graduated autonomy model: AI handles routine decisions autonomously, flags ambiguous cases for human review with recommended actions, and escalates novel situations to expert judgment with full context. This framework requires custom engineering because the boundaries between routine, ambiguous, and novel are unique to every business operation and cannot be configured through a generic platform settings panel.
The observability stack for production AI systems must capture dimensions that traditional application monitoring ignores. Beyond latency and error rates, AI systems require monitoring of output quality metrics (hallucination rates, factual accuracy scores, relevance ratings), cost efficiency metrics (cost per inference, tokens per response), and drift metrics (distribution shifts in input patterns, degradation in output quality over time). Custom observability dashboards built on Prometheus and Grafana provide this multi-dimensional visibility at a fraction of the cost of vendor-specific AI monitoring platforms that charge per-inference pricing.
The voice AI landscape in 2026 has matured dramatically. Latency—the critical factor determining whether a voice agent feels natural or robotic—has dropped below 500ms end-to-end for properly architected systems. This means voice AI agents can now handle complex multi-turn conversations with natural interruption handling, contextual memory, and real-time tool calling.
| Voice AI Dimension | Twilio + Custom Build | Vapi.ai Managed Platform |
|---|---|---|
| Setup Complexity | High (WebSocket + STT + TTS) | Low (managed orchestration) |
| Latency Control | Full (optimize each hop) | Good (pre-optimized pipeline) |
| Cost at Scale | Lower (pay per minute) | Higher (platform premium) |
| Customization | Unlimited | Template-constrained |
| Maintenance | Self-managed infrastructure | Vendor-managed updates |
Key Architecture Decisions for Voice AI
- Latency Budget: Allocate no more than 200ms to speech-to-text, 150ms to LLM inference, and 150ms to text-to-speech for natural conversation flow.
- Interruption Handling: Implement barge-in detection so callers can interrupt the AI mid-sentence without waiting for completion.
- Context Persistence: Store conversation state in Redis for sub-millisecond retrieval across turns, enabling multi-call memory.
- Tool Calling: Enable the voice agent to query databases, schedule appointments, and process payments mid-conversation via function calling.
- Fallback Routing: Automatically escalate to human agents when confidence scores drop below threshold or caller frustration is detected.
For voice AI architecture patterns, see Vapi.ai documentation and Deepgram's speech-to-text API.